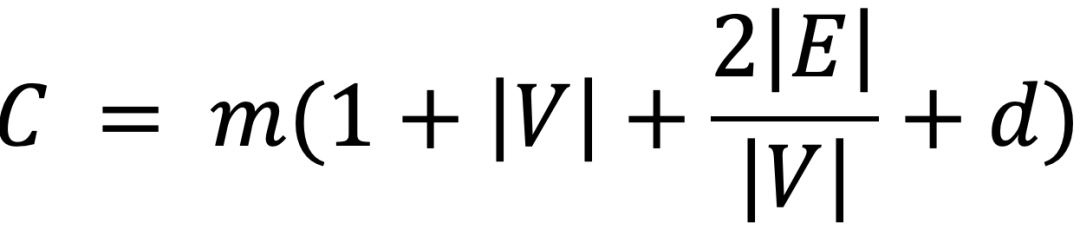AgentConductor:重构多智能体协作的拓扑演化机制——实现成本与效能的动态平衡
在软件工程范式快速迭代的背景下,开发模式已从人类手动编码转向基于智能体的自动化协作。然而,现有的多智能体系统在面对复杂工程任务时,往往陷入一种“静态工作流”困境。无论是简单的脚本编写还是复杂的系统级算法开发,系统均倾向于采用固定的交互结构,导致智能体之间的冗余通信与高昂的Token消耗。上海交通大学i-WiN中心团队提出的AgentConductor框架,正是针对这一技术痛点,通过引入强化学习驱动的动态拓扑演化机制,实现了任务难度与协作结构的自适应映射。
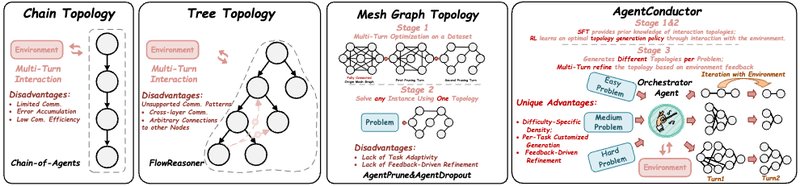
拓扑演化机制的底层逻辑解析
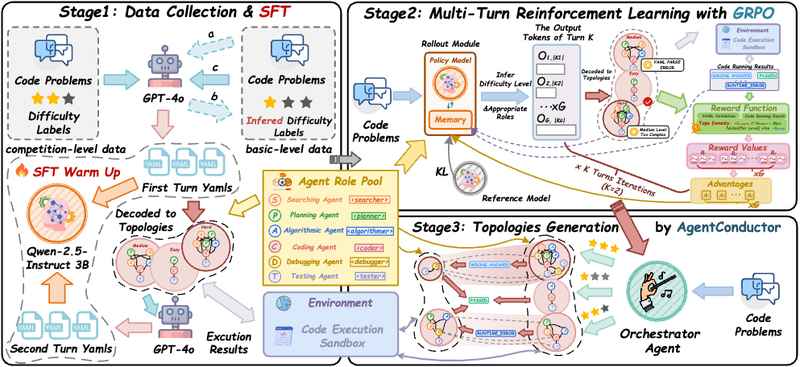
传统多智能体协作往往依赖硬编码或预定义的静态流程,这种“一刀切”的模式在面对任务难度差异时显得极为笨拙。AgentConductor的核心在于引入了一个参数量为3B的指挥智能体,该智能体通过GRPO(GroupRelativePolicyOptimization)算法进行训练,能够根据任务输入的复杂程度,实时生成一张以YAML格式表示的交互拓扑图。这种表示形式不仅具备高度的可读性,更重要的是支持程序化的校验与约束,使得大模型能够端到端地生成符合逻辑的协作结构。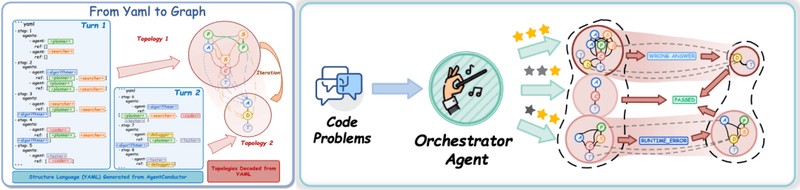
GRPO算法在拓扑生成中的技术优势
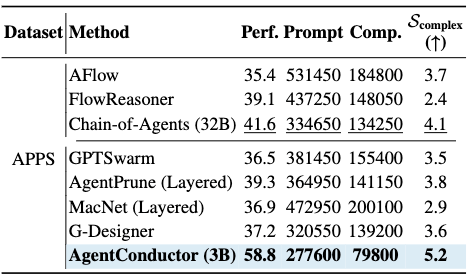
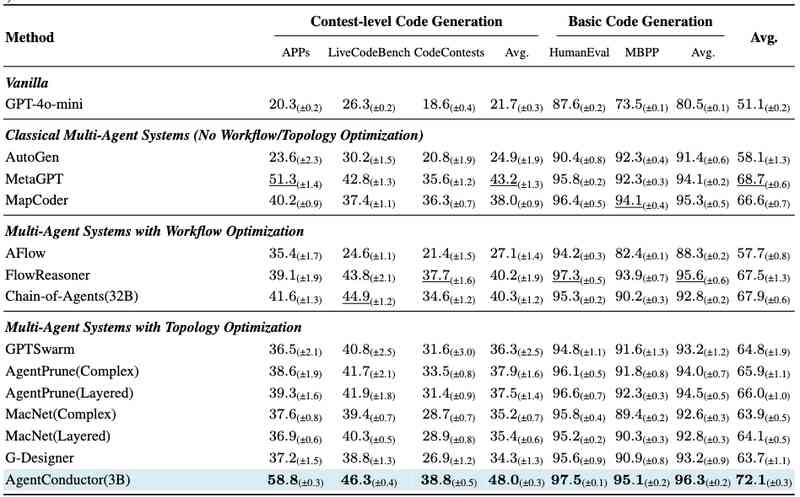
该框架采用了SFT与GRPO的两阶段训练范式。在监督微调阶段,团队利用GPT-4o生成的4500个高质量拓扑样本,为模型注入了基础的拓扑先验知识。随后的GRPO阶段则引入了环境反馈机制,将代码报错信息与拓扑结构文本作为轨迹数据,优化模型的生成策略。这种方法不仅显著降低了无效的通信成本,还将编码准确率提升了14.6%。通过引入拓扑密度评估函数,系统能够精确计算节点数、边密度与图深度对通信开销的影响,确保在保障代码质量的前提下,最大程度压缩Token成本,最终实现高达68%的成本削减。
面向任务的动态协作范式构建
AgentConductor证明了多智能体系统不再需要通过堆叠模型数量来换取性能。通过将任务难度评估、执行反馈循环以及通信成本优化统一纳入强化学习框架,该系统能够在简单任务中维持极简的协作链路,并在复杂任务中自动演化出多层级的交互结构。这种动态演化能力标志着多智能体研究从静态流程管理向自主决策演化迈进。对于开发者而言,这意味着在未来的AI编程实践中,能够以更低的算力成本,获得更具深度的工程解决方案,彻底摆脱了过去为了追求性能而必须支付高额Token费用的技术桎梏。